- Drop out of research. We recognise climate change is an urgent problem and that many scientific research projects have very indirect, uncertain, and long-term payoffs. For the most part, the problem of climate change is fairly well analysed and many solutions are known, but in need of political organisation in order to carry them out. Perhaps really what is needed is for more people to "roll up their sleeves" and join a movement or organisation that's fighting towards this.
- Engage in action research/participatory research. If you decide to stay in research then we propose that you ground your studies by working on problems that you can be sure real stakeholders have. In particular, we suggest that you start with a stakeholder that is directly involved in solving the problem (e.g. activists, scientists, journalists, politicians) and that you work with throughout your study. At the most basic level, they act as a reality-check for your ideas, but we think that the best way to make this relationship work is through action research: joining their organisation to solve their problems, becoming directly involved in the solutions yourself. Finding publishable results is an added bonus which is secondary to the pressing need.
- Elicit the requirements of real world stakeholders. As you can see from the last point, we're concerned that as software researchers we lack a good understanding of the problems holding us (society) back from dealing with climate change effectively. So, we suggest a specific research project that surveys all the actors to figure out their needs and the place the software research can contribute. This project would involve interviewing activists, scientists, journalists, politicians, and citizens to build a research roadmap.
- Green metrics: dealing with accountability in a carbon market. This idea is more vague, but simply a pointer to an area where we think software research may have some applicability. Assuming there is a compliance requirement for greenhouse gas pollution (e.g. a cap and trade system), then we will need to be able to accurately measure carbon emissions on all levels: from industry to homes.
- Software for emergencies. Like the last point, this is one rather vague. The idea is this: in doomsday future scenarios of climate change, the world is not a peaceful place. Potentially more decision-making is done by people in emergency situations. This context shift might change the rules for interface design: where say, in peacetime, a user might be unwilling to double-click on a link, or might be willing to spend time browsing menus, but in a disaster scenario their preferences may change. So, how exactly does a user's preferences change in an emergency, and how might we design software to adjust to them?
- Make video-conferencing actually easy. This was our experience all through the day:
 If we ever want to maintain our personal connections without traveling we need to solve this problem. You'd think that we had already solved it, as we have the basic technology already in place. We have Skype, it is just too flakey for relying on for important gatherings. Or, maybe, hotels and conference centres can't deal with the bandwidth demands. Or, maybe conference organisers don't make remote attendance a priority.
If we ever want to maintain our personal connections without traveling we need to solve this problem. You'd think that we had already solved it, as we have the basic technology already in place. We have Skype, it is just too flakey for relying on for important gatherings. Or, maybe, hotels and conference centres can't deal with the bandwidth demands. Or, maybe conference organisers don't make remote attendance a priority.
Even getting us through the basic technological obstacles may not be enough for a rich conference participation. Simply having a video and audio feed doesn't compare to face-to-face conversations. Maybe it never will, but certainly we can do better?
Morning discussion for the WSRCC
Monday, October 26, 2009
This morning Jorge and I attempted to attend the Workshop on Software Research on Climate Change via a skype phone call. But Skype wasn't cooperating. So, we had our a own mini-workshop ourselves. The purpose of the workshop is to respond to the challenge, "how can we apply our research strengths to make significant contributions to the problems of mitigation and adaptation of climate change?" But we interpreted the question as, "What can software researchers do to make significant contributions.... ?" As a result, we considered some alternatives that are probably out of scope for the workshop.

Position papers from the 1st Intl. Workshop on Software Research and Climate Change
Sunday, October 25, 2009
Tomorrow the First International Workshop on Software Research and Climate Change is being held as part of the Onward! 2009 conference in Florida. Jorge and I are going to attempt to attend the workshop remotely, so wish us luck. I'll be blogging about the experience tomorrow.
To begin, and as a refresher, I thought I'd post a single sentence summary of each of the position papers submitted for this workshop. Position papers were solicited from participants and were to respond to the challenge stated on the opening page of the workshop. In summary, the challenge is: how do we apply our expertise in software research to save our butts from certain destruction due to climate collapse. Or, as Steve puts it, "how can we apply our research strengths to make significant contributions to the problems of mitigation and adaptation of climate change."
In answer to that challenge, the position papers suggest software research should...
"Data Centres vs. Community Clouds", Gerard Briscoe and Ruzanna Chitchya
... tackle the energy inefficiency of cloud computing by investigating decentralised models where consumer machines also become providers and coordinators of computing resources.
"Optimizing Energy Consumption in Software Intensive systems", Arjan de Roo, Hasan Sozer and Mehmet Aksit
... provide the tools and design patterns for building software systems that meet both their energy-consumption requirements and their functional design requirements.
"Modeling for Intermodal Freight Transportation Policy Analysis", J. Scott Hawker
... improve three aspects of decision-making tools (like, say, an intermodal freight transportation policy analysis model): make them easier to use and interact with (HCI-wise); deal with the complexity of the models and the troubles with integrating various existing implementations; as well as (my favourite), make sure the software is built well since most of the folks doing the building are not trained.
"Computing Education with a Cause", Lisa Jamba
... investigate how to involve computer science students in research "toward improving health outcomes related to climate change" as part of the university curriculum.
"Some Thoughts on Climate Change and Software Engineering Research", Lin Liu, He Zhang, and Sheikh Iqbal Ahamed
... investigate how to navigate and integrate knowledge from many different disciplines and perspectives so as to help people communicate and work together; build decision-support, analysis and educational tools for people, companies, and government; build tools for incorporating environmental non-functional requirements into software construction.
"Refactoring Infrastructure: Reducing emissions and energy one step at a time", Chris Parnin and Carsten Görg.
... use insights from software refactoring to develop refactoring techniques for physical infrastructure (energy grid, water supply, etc.).
"In search for green metrics", Juha Taina and Pietu Pohjalainen
... establish a "framework for estimating or measuring the effects of a software systems' effect on climate change."
"Enabling Climate Scientists to Access Observational Data", David Woollard, Chris Mattmann, Amy Braverman, Rob Raskin, and Dan Crichton
... build systems to help climate scientists locate, transfer, and transform observational data from disparate sources.
"Context-aware Resource Sharing for People-centric Sensing", Jorge Vallejos, Matthias Stevens, Ellie D’Hondt, Nicolas Maisonneuve, Wolfgang De Meuter, Theo D’Hondt, and Luc Steels.
... investigate how to use our everyday hand-held devices as sensors to provide fine-grained environmental data.
"Language and Library Support for Climate Data Applications", Eric Van Wyk, Vipin Kumar, Michael Steinbach, Shyam Boriah, and Alok Choudhary
... build language extensions and libraries to make climate data analysis easier and more computationally efficient.
To begin, and as a refresher, I thought I'd post a single sentence summary of each of the position papers submitted for this workshop. Position papers were solicited from participants and were to respond to the challenge stated on the opening page of the workshop. In summary, the challenge is: how do we apply our expertise in software research to save our butts from certain destruction due to climate collapse. Or, as Steve puts it, "how can we apply our research strengths to make significant contributions to the problems of mitigation and adaptation of climate change."
In answer to that challenge, the position papers suggest software research should...
"Data Centres vs. Community Clouds", Gerard Briscoe and Ruzanna Chitchya
... tackle the energy inefficiency of cloud computing by investigating decentralised models where consumer machines also become providers and coordinators of computing resources.
"Optimizing Energy Consumption in Software Intensive systems", Arjan de Roo, Hasan Sozer and Mehmet Aksit
... provide the tools and design patterns for building software systems that meet both their energy-consumption requirements and their functional design requirements.
"Modeling for Intermodal Freight Transportation Policy Analysis", J. Scott Hawker
... improve three aspects of decision-making tools (like, say, an intermodal freight transportation policy analysis model): make them easier to use and interact with (HCI-wise); deal with the complexity of the models and the troubles with integrating various existing implementations; as well as (my favourite), make sure the software is built well since most of the folks doing the building are not trained.
"Computing Education with a Cause", Lisa Jamba
... investigate how to involve computer science students in research "toward improving health outcomes related to climate change" as part of the university curriculum.
"Some Thoughts on Climate Change and Software Engineering Research", Lin Liu, He Zhang, and Sheikh Iqbal Ahamed
... investigate how to navigate and integrate knowledge from many different disciplines and perspectives so as to help people communicate and work together; build decision-support, analysis and educational tools for people, companies, and government; build tools for incorporating environmental non-functional requirements into software construction.
"Refactoring Infrastructure: Reducing emissions and energy one step at a time", Chris Parnin and Carsten Görg.
... use insights from software refactoring to develop refactoring techniques for physical infrastructure (energy grid, water supply, etc.).
"In search for green metrics", Juha Taina and Pietu Pohjalainen
... establish a "framework for estimating or measuring the effects of a software systems' effect on climate change."
"Enabling Climate Scientists to Access Observational Data", David Woollard, Chris Mattmann, Amy Braverman, Rob Raskin, and Dan Crichton
... build systems to help climate scientists locate, transfer, and transform observational data from disparate sources.
"Context-aware Resource Sharing for People-centric Sensing", Jorge Vallejos, Matthias Stevens, Ellie D’Hondt, Nicolas Maisonneuve, Wolfgang De Meuter, Theo D’Hondt, and Luc Steels.
... investigate how to use our everyday hand-held devices as sensors to provide fine-grained environmental data.
"Language and Library Support for Climate Data Applications", Eric Van Wyk, Vipin Kumar, Michael Steinbach, Shyam Boriah, and Alok Choudhary
... build language extensions and libraries to make climate data analysis easier and more computationally efficient.
Modeling the solutions to climate change
Tuesday, October 20, 2009
For the past couple of weeks a few of us in the software engineering group have been meeting to take up Steve's modeling challenge: we are attempting to model (visually, not computationally) the proposed solutions from several popular books. The idea is to do so so that it's possible (easy?) to compare the differences and similarities between them. Here is the homepage* for the project, which roughly tracks what we're up to. I'm going to summarise our progress so far.



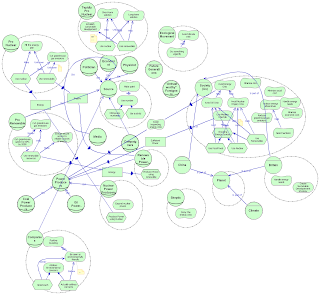
To start off, we narrowed our focus down to just comparing the books by their take on wind power solutions. We began with David McKay's excellent book, Sustainable Energy -- without the hot air.
In our first few meeting we decided to just "shoot first and ask questions later". That is to say, we just collaborative built up a model of the chapters on wind power as we saw fit in the moment, without following any visual syntax and without worrying too much about what to include or what to ignore. The result looked like this:

At the bottom of that picture is our brainstorming about what other aspects to include (the left hand column), the types of perspectives/analysis that McKay uses and that may be useful to include a future exercise (middle column), and the types of differences we expect to see when comparing models (right column).
The next step would have been to come up with the same sort of model for another book, and then start to figure out how best to make the models comparable so that it is visually easy to see the differences and similarities between the various models.
We didn't do that. Instead, we decided to try making a more principled model. Actually, set of models. We decided to construct an entity-relationship (ER) model, and a goal model (i*) for two books and then see about how to go about making those models comparable.
We began with the entity-relationship model. Again, for McKay's book. McKay's book is fairly well segmented into chapters that have back-of-the-envelope-style analysis and others that have a more broad discussion of the actors and issues. In our first attempt shown above, we mainly only modeled the two chapters on wind-power analysis. But if we just stuck to those chapters for the ER and goal models we'd be left with very impoverished models that miss all of the important contextual bits that frame the wind-power discussion. We relaxed the restriction on our wind-power focus slightly so as to include parts of the book that discuss the context. In the case of McKay's book, chapter one covers this nicely.
After our first few meetings we've completed the ER domain model, as well as made a good start on the goal model.
For the wider context (chapter one), we built the following ER model:

This model is a bit of a monster, but I'm told that most models are like that. Other than the standard UML relationship syntax, we have coloured the nodes to represent whether the concept comes from the book directly (blue), or whether we included it because we felt it was implied or simply helpful for clarity (yellow).
Using the same process we created the following ER model for just the two chapters on wind:

As well, we've begun to go back over the first chapter and build up an i* goal model. Here it is so far:

Stay tuned for further updates on what we're up to. I'd suggest that at the moment these models should simply be taken as our first hack. We haven't done any work whatsoever to make them very readable or comparable, for instance.
* I feel like "homepage" is a rather outdated word now. Is that so?
Geoscientific Model Development
Sunday, October 18, 2009
I had an wonderful chat last week with Stephen Griffies from GFDL. It was a fascinating interview that I'll have to blog about over several posts because we just covered so much territory.
One especially interesting pointer Stephen gave me was to a new journal from European Geosciences Union titled Geoscientific Model Development. This is a journal that accepts articles about the nuts and bolts of building modelling software. It is apparently the only journal like it. Most of the other journals that climate scientists publish in will only accept papers on the "science" derived from the use of such models.
For those of us interested in how climate models are developed, this journal will likely be very relevant. What I find particular cool is the transparent peer-review process and open-discussion. This means for a particular article (say, this one on coupling software for earth-system modelling), you can read the paper and the current referee reviews (with the option to submit your own comments).
One issue with the journal Stephen mentioned is that it is currently not listed in any of the major scientific citation indices. Effectively this means that scientists do not get workplace "cred" for publishing in this journal. Thus, there is little motivation to publish even though, as Stephen put it, having a peer-reviewed publication to "rationalise" code and design decisions is essential to ensuring the scientific integrity of the models.
Talk: Climate Change & Psychological Barriers to Change
Tuesday, September 22, 2009
This week is Earthcycle at U of T: an environment week with many many great happenings (see the link for more info). In particular there is what looks to be a great lecture on Thursday discussing the recent report on psychology and climate change from the American Psychological Association.
Here's the full posting:
Thurs. Sept. 24
7:00 p.m. – 9:00 p.m.
Lecture Climate Change & Psychological Barriers to Change, with Dr. Judith Deutsch ( Science for Peace) & Prof. Danny Harvey ( U of T)
International Student Centre, Cumberland Room
33 St. George Street
This is, in part, a summary of a major conference by the Report by the American Psychological Association’s Task Force on the Interface Between Psychology and Global Climate Change titled “Psychology and Global Climate Change: Addressing a Multi-faceted Phenomenon and Set of Challenges.”
The study includes sections on concern for climate change, not feeling at risk, discounting the future, ethical concerns, population issues, consumption drivers, counter-consumerism movements, psychosocial and mental health impacts of climate change, mental health issues associated with natural and technological disasters, lessons from Hurricane Katrina, uncertainty and despair, numbness or apathy, guilt regarding environmental issues, heat and violence, displacement and relocation, social justice implications, media representations, anxiety, psychological benefits associated with responding to climate change, types of coping responses, denial, judgmental discounting, tokenism and the rebound effect, and belief in solutions outside of human control.
A copy of the report is available at http://www.apa.org/science
Dr. Judith Deutsch is a psychiatric social worker and President of Science for Peace.
Prof. Danny Harvey is with the Geography Department at UofT, a member of the IPCC, and an internationally renowned climate change expert.
Organized by Science for Peace
Facebook event page:
http://www.facebook.com/event.php?eid=131392308428&index=1
On static analysis
Monday, August 31, 2009
Last week I got serious about running a thorough static analysis (using Cleanscape's FortranLint) of one of the climate modelling packages I'm studying. It turns out to be trickier than I thought just to get the source code in a state to be analysed because of the complexity and "homebrewedness" of the configuration systems used.
What do I mean? Well, the models I'm studying are complex beasts. They are composed of many of sub-models, and those sub-models themselves are built from sub-sub-models. For example, a global climate model may be composed of an atmosphere model, an ocean model, and a land model. These sub-models are often functioning models in their own right and can often be run separately. And as I say, the sub-models are also built up from various models. The ocean model may have a sea-ice model, a biogeochemical model, and an ocean dynamics model. There may also be different versions of these sub- or sub-sub models being actively developed.
There are also piles and piles of configuration options for each of these components (the models, the sub-models, the sub-sub-models).
Thus, the climate model code shouldn't really be thought of in the singular sense. It's not source code for a climate model, but for an almost infinite number of different climate models depending on which sub-, or sub-sub-models are included in a particular build, and which configuration options are used.
A word on configuration options. The configuration system for some of the climate models I'm looking at are very complex (as you might expect). They include a generous helping of C preprocessor (CPP) instructions to include or remove chunks of code or other files in order to get just the right bits of functionality. As well, there are many makefiles and home-brewed scripts to assemble and ready the appropriate source files for compilation (e.g. move only the files land ice model version 2 files, not version 1 files, and rename them like so, etc..). Of course, there are also plenty of run-time configuration options slurped in from configuration data files (but since that happens after compilation it's not a concern to me when doing static analysis).
The upshot of all of this is that the source code for a climate model isn't shipped in a state that can be run through static analysis. In order for the static analysis tool to do it's job, it needs to be handed the source code in a ready-to-compile state. After all, the static analysis tool is an ultra-picky compiler that doesn't actually do any compilation but instead just spits out warnings about the structure of the code.
(I'm simplifying slightly: both of the static analysis tools I've looked at (FortranLint and Forcheck) both offer the ability to handle some preprocessing statements. Forcheck implemented it's own limited CPP-style preprocessor, and FortranLint will just call cpp for you on the file. Thus, it is possible to hand the static analysis tool code that isn't exactly in a compilable state, but you still need to configure the static analysis tool to do all the preprocessing... and that essentially duplicates the work that's being done by the homebrewed scripts and Makefiles).
The trouble is that getting a snapshot of the code that's ready for compilation isn't a trivial task. The homebrewed scripts and makefiles do a lot of magic as I described above. Somewhere in that magic -- and often not in one nice, distinct stage -- the code gets compiled. That is, no where in the process is there a folder of preprocessed, ready-to-compile files: configuration and compilation are bound up together.
Ideally I'd like to be able to run the configuration/compilation scripts up to the point in which they produce the ready-to-compile code, then run my static analysis tools over the code, and then continue on with the compilation process so that I can be sure that the code I'm analysing is exactly the code is able to be compiled into a working model. That would be the ultimate validation that I'm analysing the correct code, right? (If I were to use the built in preprocessing facilities of the static analysis tools I can never be sure that I've exactly duplicated the work done in the configuration scripts).
Unfortunately, this separation of configuration and compilation can't be done with out deeply understanding and re-writing the configuration scripts. hmmm... That's one option. It's more messy than I'd like it to be, but I might need to do it to remove any doubts about the validity of my results.
The other option I've come up with is a bit more cavalier, but still might be justifiable. It goes like this: redirect all calls to the compiler in the makefiles to a script that simply copies the target file to another location first before doing the actual compilation. The idea here is to intercept right at the point of compilation in order to take a snapshot of only those files that are compiled and when their in their proper configured and preprocessed state.
In fact, since I don't care about actually compiling the model, the stand-in compiler script could simply output an empty file instead of the actual compiled file. (Outputting an empty file is necessary in order to make other steps of the makefile happy and believe some real work was done.) Of course, replacing the compiler with something that doesn't actually do any compilation also requires that another programs in the makefiles that expect real work to have been done (i.e. the archiving tool, ar) must also be redirected to dummy scripts.
The result would be a folder full of ready-to-compile source files that should, in theory, all be able to be compiled together to make the climate model, and thus ready to be fed to the static analysis tool.
Also, in theory, and with less of a deeper understanding of the climate models, I should be able to compile the files I get from this process into a binary file that I can compare to the binary produced by the unadulterated configuration/compilation process in order to validate this hack.
Where I'm at: I tried putting this process in place last week with one of the models. I successfully got a nice pile of source files to analyse. I'm now just dealing with configuring the static analysis tool to handle external dependencies, but I should know soon whether this idea will work or not.
Abstract of my study for the AGU
I'm submitting an abstract of my study for the Methodologies of Climate Model Confirmation and Interpretation" session at the American Geophysical Union's Fall Meeting in December. This session (either poster or paper) is aimed at exploring the "methodological issues surrounding the confirmation, evaluation, and interpretation of climate and integrated assessment models".
Here's the current draft of the abstract. I've found it a little tricky to write an abstract for work that I haven't yet completed but I've given it a go. I've gotten some excellent feedback from some of my colleagues (big up to: Steve, Neil, Jono, and Jorge) as to how to frame the problem and my "results" (in quotations because I don't yet have concrete results).
Here's the current draft of the abstract. I've found it a little tricky to write an abstract for work that I haven't yet completed but I've given it a go. I've gotten some excellent feedback from some of my colleagues (big up to: Steve, Neil, Jono, and Jorge) as to how to frame the problem and my "results" (in quotations because I don't yet have concrete results).
Feedback on clarity, wording, grammar, framing of the problem and results, etc... are very much welcome.On the software quality of climate models
A climate model is an executable theory of the climate; the model encapsulates climatological theories in software so that they can be simulated and their implications investigated directly. Thus, in order to trust a climate model one must trust that the software it is built from is robust. Our study explores the nature of software quality in the context of climate modelling: How do we characterise and assess the quality of climate modelling software? We use two major research strategies: (1) analysis of defect densities -- an established software engineering technique for studying software quality -- of leading global climate models and (2) semi-structured interviews with researchers from several climate modelling centres. We collected our defect data from bug tracking systems, version control repository comments, and from static analysis of the source code. As a result of our analysis, we characterise common defect types found in climate model software and we identify the software quality factors that are relevant for climate scientists. We also provide a roadmap to achieve proper benchmarks for climate model software quality, and we discuss the implications of our findings for the assessment of climate model software trustworthiness.
Subscribe to:
Posts (Atom)
